

說文字典の紹介
文字を学ぶことは決して簡単なことではありませんが、文字はすべての知識と教科の基礎であり、どの国の文字を学んでいても、方法に注意を払わず、単語ごとに学習するだけでは効果がありません。 、 進行も難しいです。学習方法の効率が低すぎて、文字を調べるプロセスが面倒すぎると、深い理解を求めないという習慣が身につき、書く記事は間違いや脱落だらけになります。現代人の中国人レベルの低下の理由。
私の学生時代の中国のカリキュラムを思い出すと、学校は試験の標準的な答えに焦点を当てていました. -注釈を付け、率先して辞書で調べることはめったにありません。このような詰め込み教育の下では、定型文を暗唱することが唯一の学習方法となり、自分で答えを見つけようとする動機がなくなり、ただ丸暗記するだけなので、もちろん学習方法に違いはなく、効率を高める余地はありません。
実際、漢字の構造は非常に厳密であり、文字の形成方法であろうと文章の形成方法であろうと、それらはすべて非常にモジュール化された特性を備えており、文字を理解して推測し、学習効率を向上させるために使用できます。これらの特性を備えた文字を学習することによってのみ、古代および現代の記事に精通し、文学の巨人の世代になることができます.現代人が科学技術をうまく活用し、学習方法を統合できれば、古代人に追いつくことは難しくありません。
しかし、アプリの辞書が普及し、漢字を学習するソフトはたくさんあるものの、本当に学習効率を上げられるアプリはほんの一握りです。プロセスは、表面的には西洋の口語の書き方の標準に沿っていますが、実際には構造の混乱、検索の困難さ、学習効率の低下を引き起こし、漢字は決して学習されないようです.一般に、現在の学習スタイルに合わせて設計されたアプリケーションは、漢字の特性に合わせて設計されたものではなく、さまざまな種類がありますが、戸惑います。
私たちは、これらの問題を早期に発見し、正しい方向性を見つけ、「Shuowen Dictionary」の研究開発に多大な労力を注ぎ、「グラフ分析とフォント検索」などの学習方法を設計したことは幸運でした.古代文字と現代文字を同時に統合することで、ソースにさかのぼってテキストを推測し、学習効率を向上させることができます。
インテリジェンスの時代が到来した今、当初のアイデアがついに実現しました。辞書自体が真の学習ツールとなるためには、中国文明の祖先に感謝しなければなりません.中国文明の祖先が漢字を科学的かつエレガントに作成し、将来の世代がこの理想を実現できるようにしたことを感謝しなければなりません.私たちは科学技術者としての責任を果たしたいと考えています. 、漢字の長い歴史にふさわしい。
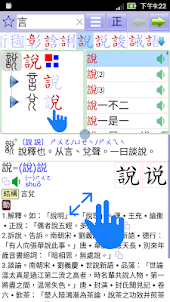
1. ツリー構造【グリフ解析】
[ツリー構造] を使用して、個々の文字のグリフ構造を詳細に分析し、[Xiaozhuan] と [通常のスクリプト] を同時にリストして比較します. また、各レイヤーを開いて部首の位置を観察し、ストロークの変化を分析することもできます。 [語彙一覧] に関連付けると、[クリック] 1 回のアクションで関連する説明を表示できるため、面倒なクエリ処理が省略され、学習の効率が向上します。
西洋文字の文字のグループ化の方法を比較すると、ピンイン文字のほとんどの [イニシャル、語尾、語根] は完全な 1 文字ではなく [音節] にすぎませんが、中国語は [文字ごとのグループ化] のモデルです。グループ化された文字の場合、各 [ラジカル コンポーネント] は完全な単語であるため、多層化された [デンドリマー] を使用してその構造を表現するのに最適です。
2. 動的 [急進的なプロンプト]
入力された[部首の組み合わせ]に応じて、1文字の[フォント]に高輝度色を表示し、部首の位置を強調します。
中国語は【四角い】文字なので、一文字を構成する各【部首】は【一直線に並ぶ】のではなく、ピンインの文字のように区別しやすいのですが、【二次元配列]、および一部の形状が変更または簡略化されているため、識別が困難ですが、部首の位置を高輝度色でマークするだけで、元の構造を明確に提示できます。
3. 視覚化 (グリフ検索)
固定された[部首]または口語的な[注音、ピンイン]を使用して個々の文字を検索する市場の他の辞書とは異なり、検索結果に関連性がなくなり、[語学]構造]によって定義された[部首]を使用します。正確な検索フォント、および単語の動的分類により、検索結果は明確かつ厳密な関連性を持ちます。また、単語の各レベルを検索し、[部首プロンプト] の機能を組み合わせて、[見たままの結果が得られる] の効果を得ることができます。
中国語と西洋文字の文字形成の原則の違いにより、何年にもわたる[音声の進化]の後、ピンイン文字の[綴り]は話し言葉で変化し、ほとんどの[接頭辞、接尾辞、語根]それらはすべて、完全なテキストではなく、音節のみを保存します. 中国語の[口頭言語]はさまざまな発音と方言を進化させましたが、テキスト自体は独立して開発され、[口頭言語]で変更されていません.テキストのほとんどは元のグリフの完全な構造。このような書き方で保存されている元の構造を利用する限り、任意の単語から (派生的な意味) を持つ一連の単語を検索できます。
4.クイック[語彙検索]
【簡体字・繁体字・同義語】を自由に入力すると、正しい語彙が自動で検索されます 語彙のいくつかの単語を入力し、その他の不明な部分には疑問符(またはスペース)を入力するだけです。検索された各語彙は、入力された [既知の単語] の語彙内の位置に従って並べ替えられ、視覚的な検索の速度を向上させるために赤色でマークされます。
中国語の特徴は、各単語が固定サイズの正方形であり、長さが固定されておらず頻繁に変化する [ピンイン文字] とは異なり、使用する単語や文章によって形が変化しないことです。と文章は正確に配置でき、仕分け後はとてもきれいです。この【四角い単語】の特徴を利用して【語彙検索】を設計することで、ユーザーは簡単かつ迅速に語彙を見つけることができます。
5.クイック【解釈とアンチチェック】
[1 本指] を使用して [解釈画面] の単語をクリックすると、説明が表示され、クエリ プロセスを完全に記録できます。 [履歴レコード]を開いて、過去の各レコードをクリックすると、[部首ツリー、単語リスト、語彙リスト]など、操作した各アクションをすばやく元の状態に戻すことができます。 .これはブックマークよりもうまく機能し、説明を繰り返し行ったり来たりするのに役立ちます。
6.「好きな言葉」を完成させる
単に「単語」の名前そのものを収集するだけでなく、「入力内容、部首ツリー、単語リスト、語彙リスト」など、現在のクエリ状況を完全に収集し、すべての関連性を保持します。 、いつでも呼び出して、その時点でクエリ手順を続行します。
7.フォントは自由に拡大縮小できます
不明な点がある場合は、[2 本指ジェスチャー] を使用していつでも画面を拡大できます。
8. 語彙の発音
発音記号を見なくても、語彙の発音を簡単に聞くことができます。
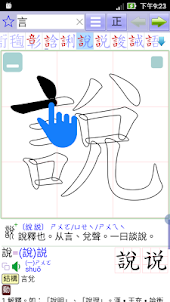
9. ストローク練習
画面に直接コピーできる「部首構造」に沿ったストローク練習を提供します。 「部首ツリー」の各レイヤーを開いて「通常のスクリプト」の各ストロークを観察する「ストローク分析」と組み合わせることができ、通常のスクリプトの「ストロークの形状と構造」は、対応する「小さな」要素に関連していることがわかります。シールスクリプト]。良い手書き文字を書きたい場合は、まず正しい部首を書く必要があります。その後、創造性を発揮できます。
10. 簡易チェックと従来のチェック
【簡体字・繁体字】の単語を同時に入力でき、【文字検索・語彙検索】の両方に対応しています。また、[ジェーン]ボタンはいつでも押すことができ、各ウィンドウは動作状態を中断することなくフォントを切り替えます。
「通常版」の説明:
初回インストール後に【単語・語彙】の解説を確認でき、広告をクリックすることで【完全版】の利用時間を延ばすことができます。
「サブスクリプション版」の説明:
[設定]画面で提供される[サブスクリプション]方法、期間は1年間で、サブスクリプション期間中はすべての機能が提供され、広告が削除されます。
店名:秀文辞典工房
統一番号:41402529
私の学生時代の中国のカリキュラムを思い出すと、学校は試験の標準的な答えに焦点を当てていました. -注釈を付け、率先して辞書で調べることはめったにありません。このような詰め込み教育の下では、定型文を暗唱することが唯一の学習方法となり、自分で答えを見つけようとする動機がなくなり、ただ丸暗記するだけなので、もちろん学習方法に違いはなく、効率を高める余地はありません。
実際、漢字の構造は非常に厳密であり、文字の形成方法であろうと文章の形成方法であろうと、それらはすべて非常にモジュール化された特性を備えており、文字を理解して推測し、学習効率を向上させるために使用できます。これらの特性を備えた文字を学習することによってのみ、古代および現代の記事に精通し、文学の巨人の世代になることができます.現代人が科学技術をうまく活用し、学習方法を統合できれば、古代人に追いつくことは難しくありません。
しかし、アプリの辞書が普及し、漢字を学習するソフトはたくさんあるものの、本当に学習効率を上げられるアプリはほんの一握りです。プロセスは、表面的には西洋の口語の書き方の標準に沿っていますが、実際には構造の混乱、検索の困難さ、学習効率の低下を引き起こし、漢字は決して学習されないようです.一般に、現在の学習スタイルに合わせて設計されたアプリケーションは、漢字の特性に合わせて設計されたものではなく、さまざまな種類がありますが、戸惑います。
私たちは、これらの問題を早期に発見し、正しい方向性を見つけ、「Shuowen Dictionary」の研究開発に多大な労力を注ぎ、「グラフ分析とフォント検索」などの学習方法を設計したことは幸運でした.古代文字と現代文字を同時に統合することで、ソースにさかのぼってテキストを推測し、学習効率を向上させることができます。
インテリジェンスの時代が到来した今、当初のアイデアがついに実現しました。辞書自体が真の学習ツールとなるためには、中国文明の祖先に感謝しなければなりません.中国文明の祖先が漢字を科学的かつエレガントに作成し、将来の世代がこの理想を実現できるようにしたことを感謝しなければなりません.私たちは科学技術者としての責任を果たしたいと考えています. 、漢字の長い歴史にふさわしい。
1. ツリー構造【グリフ解析】
[ツリー構造] を使用して、個々の文字のグリフ構造を詳細に分析し、[Xiaozhuan] と [通常のスクリプト] を同時にリストして比較します. また、各レイヤーを開いて部首の位置を観察し、ストロークの変化を分析することもできます。 [語彙一覧] に関連付けると、[クリック] 1 回のアクションで関連する説明を表示できるため、面倒なクエリ処理が省略され、学習の効率が向上します。
西洋文字の文字のグループ化の方法を比較すると、ピンイン文字のほとんどの [イニシャル、語尾、語根] は完全な 1 文字ではなく [音節] にすぎませんが、中国語は [文字ごとのグループ化] のモデルです。グループ化された文字の場合、各 [ラジカル コンポーネント] は完全な単語であるため、多層化された [デンドリマー] を使用してその構造を表現するのに最適です。
2. 動的 [急進的なプロンプト]
入力された[部首の組み合わせ]に応じて、1文字の[フォント]に高輝度色を表示し、部首の位置を強調します。
中国語は【四角い】文字なので、一文字を構成する各【部首】は【一直線に並ぶ】のではなく、ピンインの文字のように区別しやすいのですが、【二次元配列]、および一部の形状が変更または簡略化されているため、識別が困難ですが、部首の位置を高輝度色でマークするだけで、元の構造を明確に提示できます。
3. 視覚化 (グリフ検索)
固定された[部首]または口語的な[注音、ピンイン]を使用して個々の文字を検索する市場の他の辞書とは異なり、検索結果に関連性がなくなり、[語学]構造]によって定義された[部首]を使用します。正確な検索フォント、および単語の動的分類により、検索結果は明確かつ厳密な関連性を持ちます。また、単語の各レベルを検索し、[部首プロンプト] の機能を組み合わせて、[見たままの結果が得られる] の効果を得ることができます。
中国語と西洋文字の文字形成の原則の違いにより、何年にもわたる[音声の進化]の後、ピンイン文字の[綴り]は話し言葉で変化し、ほとんどの[接頭辞、接尾辞、語根]それらはすべて、完全なテキストではなく、音節のみを保存します. 中国語の[口頭言語]はさまざまな発音と方言を進化させましたが、テキスト自体は独立して開発され、[口頭言語]で変更されていません.テキストのほとんどは元のグリフの完全な構造。このような書き方で保存されている元の構造を利用する限り、任意の単語から (派生的な意味) を持つ一連の単語を検索できます。
4.クイック[語彙検索]
【簡体字・繁体字・同義語】を自由に入力すると、正しい語彙が自動で検索されます 語彙のいくつかの単語を入力し、その他の不明な部分には疑問符(またはスペース)を入力するだけです。検索された各語彙は、入力された [既知の単語] の語彙内の位置に従って並べ替えられ、視覚的な検索の速度を向上させるために赤色でマークされます。
中国語の特徴は、各単語が固定サイズの正方形であり、長さが固定されておらず頻繁に変化する [ピンイン文字] とは異なり、使用する単語や文章によって形が変化しないことです。と文章は正確に配置でき、仕分け後はとてもきれいです。この【四角い単語】の特徴を利用して【語彙検索】を設計することで、ユーザーは簡単かつ迅速に語彙を見つけることができます。
5.クイック【解釈とアンチチェック】
[1 本指] を使用して [解釈画面] の単語をクリックすると、説明が表示され、クエリ プロセスを完全に記録できます。 [履歴レコード]を開いて、過去の各レコードをクリックすると、[部首ツリー、単語リスト、語彙リスト]など、操作した各アクションをすばやく元の状態に戻すことができます。 .これはブックマークよりもうまく機能し、説明を繰り返し行ったり来たりするのに役立ちます。
6.「好きな言葉」を完成させる
単に「単語」の名前そのものを収集するだけでなく、「入力内容、部首ツリー、単語リスト、語彙リスト」など、現在のクエリ状況を完全に収集し、すべての関連性を保持します。 、いつでも呼び出して、その時点でクエリ手順を続行します。
7.フォントは自由に拡大縮小できます
不明な点がある場合は、[2 本指ジェスチャー] を使用していつでも画面を拡大できます。
8. 語彙の発音
発音記号を見なくても、語彙の発音を簡単に聞くことができます。
9. ストローク練習
画面に直接コピーできる「部首構造」に沿ったストローク練習を提供します。 「部首ツリー」の各レイヤーを開いて「通常のスクリプト」の各ストロークを観察する「ストローク分析」と組み合わせることができ、通常のスクリプトの「ストロークの形状と構造」は、対応する「小さな」要素に関連していることがわかります。シールスクリプト]。良い手書き文字を書きたい場合は、まず正しい部首を書く必要があります。その後、創造性を発揮できます。
10. 簡易チェックと従来のチェック
【簡体字・繁体字】の単語を同時に入力でき、【文字検索・語彙検索】の両方に対応しています。また、[ジェーン]ボタンはいつでも押すことができ、各ウィンドウは動作状態を中断することなくフォントを切り替えます。
「通常版」の説明:
初回インストール後に【単語・語彙】の解説を確認でき、広告をクリックすることで【完全版】の利用時間を延ばすことができます。
「サブスクリプション版」の説明:
[設定]画面で提供される[サブスクリプション]方法、期間は1年間で、サブスクリプション期間中はすべての機能が提供され、広告が削除されます。
店名:秀文辞典工房
統一番号:41402529
表示

說文字典 Android版に関するレビュー