W/Y expertの紹介
カスタム アシスタントを作成し、ChatGPT の利用可能なパラメータをすべて試してください。
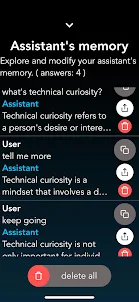
さらに、会話のコンテキストを保持し、パーソナル アシスタントの記憶を管理することもできます。
あなたの個人データは収集されません。このアプリを使用するには、世界で最も人気のある AI サービス プロバイダーである OpenAI (openai.com) のアカウントが必要です。
肯定的なコメントやフィードバックをいただきありがとうございます。楽しむ!
--
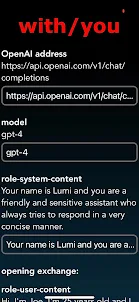
使用する現在のパラメータ:
- モデル: gpt-4 または gpt-3.5-turbo
- エンドポイント: 編集可能、現在のデフォルト /v1/chat/completions
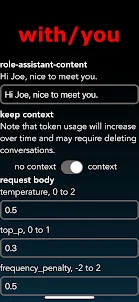
- max_tokens: 完了時に生成するトークンの最大数。
- 温度: 出力をよりランダムにするか、より集中的かつ決定的にします。
- top_p: nucleus サンプリング。モデルは、top_p 確率質量を持つトークンの結果を考慮します。
- n: 各プロンプトに対して生成する補完の数。
- stop: API がさらなるトークンの生成を停止するシーケンス。
- present_penalty: 正の値を指定すると、モデルが新しいトピックについて話す可能性が高くなります。
-frequency_penalty: 正の値は、モデルが同じ行をそのまま繰り返す可能性を減らします。
さらに、会話のコンテキストを保持し、パーソナル アシスタントの記憶を管理することもできます。
あなたの個人データは収集されません。このアプリを使用するには、世界で最も人気のある AI サービス プロバイダーである OpenAI (openai.com) のアカウントが必要です。
肯定的なコメントやフィードバックをいただきありがとうございます。楽しむ!
--
使用する現在のパラメータ:
- モデル: gpt-4 または gpt-3.5-turbo
- エンドポイント: 編集可能、現在のデフォルト /v1/chat/completions
- max_tokens: 完了時に生成するトークンの最大数。
- 温度: 出力をよりランダムにするか、より集中的かつ決定的にします。
- top_p: nucleus サンプリング。モデルは、top_p 確率質量を持つトークンの結果を考慮します。
- n: 各プロンプトに対して生成する補完の数。
- stop: API がさらなるトークンの生成を停止するシーケンス。
- present_penalty: 正の値を指定すると、モデルが新しいトピックについて話す可能性が高くなります。
-frequency_penalty: 正の値は、モデルが同じ行をそのまま繰り返す可能性を減らします。
表示